Automatic language detection
Once you have entered some text, MiMo automatically tries to detect the language. It needs to do this so it can ‘parse’ the text. This involves analysing its structure, and assigning part-of-speech tags. To detect the language, it uses an algorithm which prioritises speed over accuracy. The more text you input the more accurate the analysis.
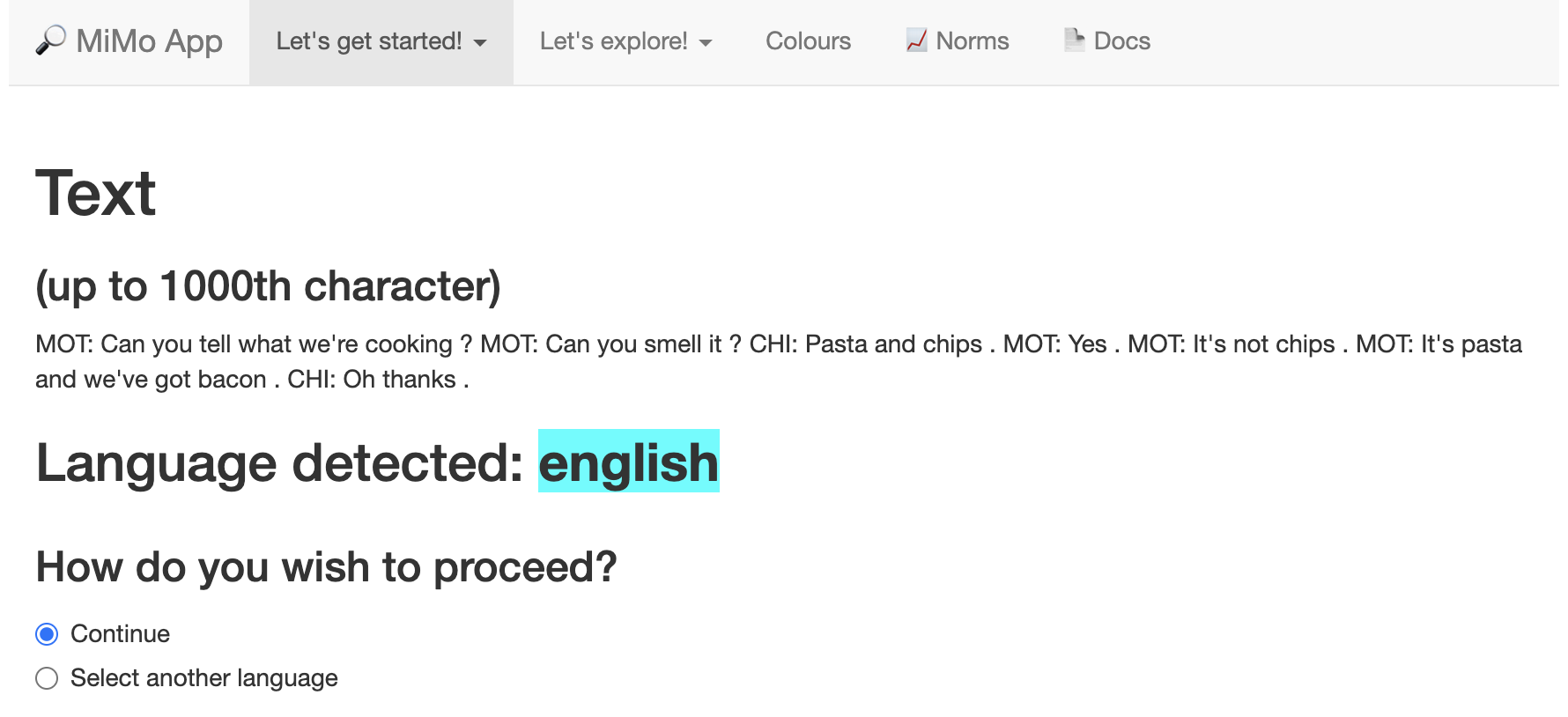
For short fragments of text, it may get things spectacularly wrong. It sometimes analyses English as Middle Frisian! If this happens, all you have to do is click Select another language specify the language in the textbox as shown below.
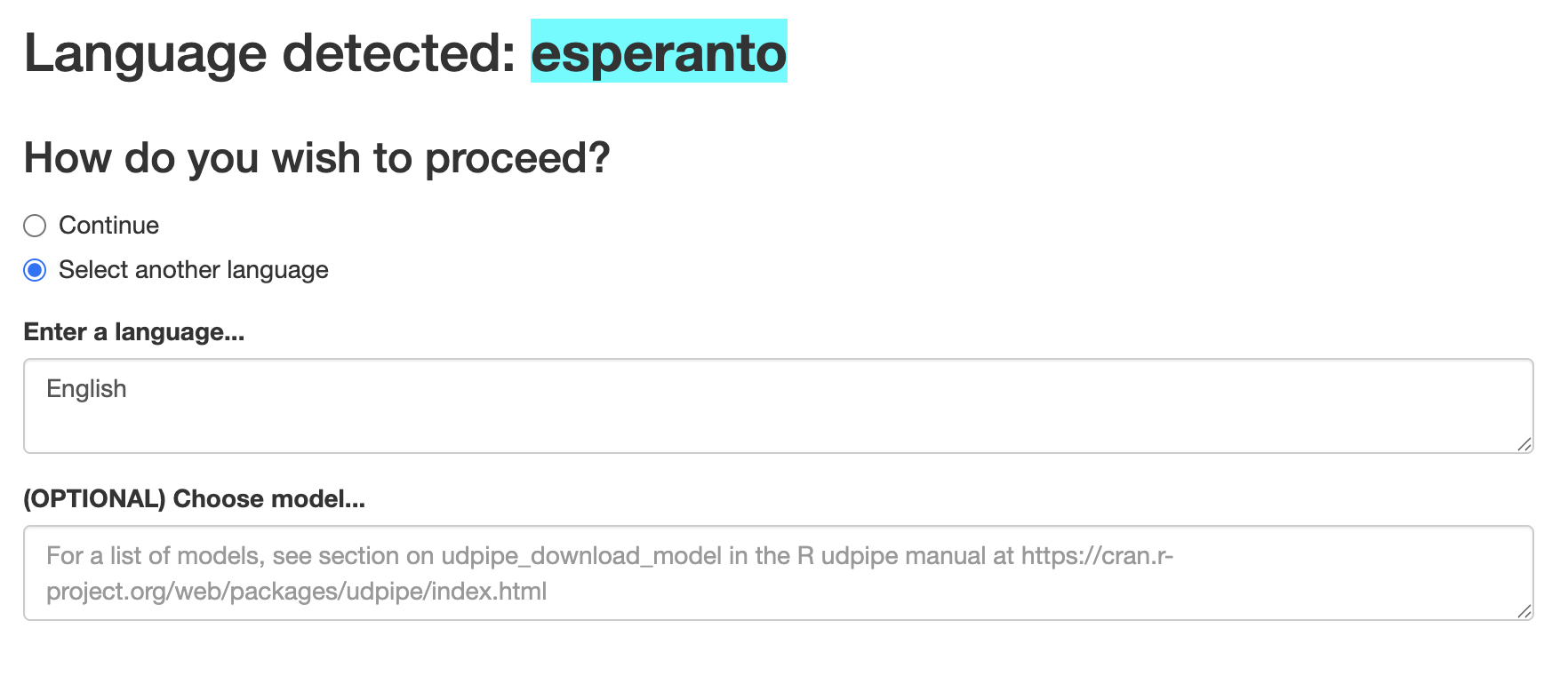
You’ll note that you also have the option to select a specific grammar from the Universal Dependencies framework. There are a number of different grammars for each language. I am not sure why anyone would wish to do this, as the default grammar is often chosen for good reasons. But it’s always good to have options!
What languages can MiMo analyse?
MiMo uses the Universal Dependencies infrastructure to analyse text. This is partly funded by Google. Once the appropriate language is detected, MiMo downloads the right Universal Dependency grammar. Grammars are available for 65 mainly European languages (some non-living), which constitute only a small minority of the world’s language. These are listed in the manual for the R udpipe library. This list is reproduced in a simplified format below;
Afrikaans, Ancient Greek, Arabic, Armenian, Basque, Belarusian, Bulgarian, Buryat, Catalan, Chinese (variety not specified), Classical Chinese, Coptic, Croatian, Czech, Danish, Dutch-alpino, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Indonesian”, Irish, Italian, Japanese, Kazakh, Korean, Kurmanji, Latin, Latvian, Lithuanian, Maltese, Marathi, North Sami, Norwegian, Old church Slavonic, Old French, Old Russian, Persian, Polish, Portuguese, Romanian, Russian, Sanskrit, Scottish Gaelic, Serbian, “slovak-snk”, Slovenian, Spanish, Swedish, Tamil, Telugu, Turkish, Ukrainian, Upper Sorbian, Urdu, Uyghur, Veitnamese, Wolof
I have only trialled the app with the major European languages, and I am not sure how it will work with languages which do not use a Roman alphabet. Do give me feedback on this!
In future I may provide an option to use Large Language Models, e.g. chatGPT and Claude, to do the Part-of-Speech tagging. This would be great for languages which are not covered by the Universal Dependencies framework. However, this would involve quite a lot of re-engineering, so I have put it on the back-burner.